Sorting Algorithms
대부분 O(n2 ) 과 O(nlogn) 사이
Input이 특수한 성질을 만족하는 경우에는 O(n) sorting도 가능하다.
1. Selection Sort (선택정렬)
다음과 같은 순서로 이루어진다.
각 루프마다
- 최대 원소를 찾는다
- 최대 원소와 맨 오른쪽 원소를 교환한다
- 맨 오른쪽 원서를 제외한다.
하나의 원소만 남을 때까지 위의 루프를 반복한다.
selectionSort(A[], n)
{
for last <- n downto 2 {
A[1...last] 중 가장 큰 수 A[k]를 찾는다;
A[k] <-> A[last]; //A[k]와 A[last]의 값을 교환
}
}
수행시간
- for 루프는 n-1 번 반복
- 가장 큰 수를 찾기 위한 비교횟수 : n-1, n-2, ... , 2, 1
마지막 교환은 상수 시간 작업
(n-1) + (n-2) + ... + 2 + 1 = O(n2 )
2. Bubble Sort (거품정렬)
거품 정렬(Bubble sort)은 두 인접한 원소를 검사하여 정렬하는 방법이다. 시간 복합도가 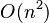 로 상당히 느리지만, 코드가 단순하기 때문에 자주 사용된다. 원소의 이동이 거품이 수면으로 올라오는 듯한 모습을 보이기 때문에 지어진 이름이다.
로 상당히 느리지만, 코드가 단순하기 때문에 자주 사용된다. 원소의 이동이 거품이 수면으로 올라오는 듯한 모습을 보이기 때문에 지어진 이름이다.
bubbleSort(A[], n)
{
for last <- n down to 2
for i <- 1 to last-1
if (A[i]>A[i+1] then A[i] <-> A[i+1]; //원소 교환
}
수행시간
- 처음 for 루프는n-1 번 반복
- 중간 for 루프는 각각 n-1, n-2, ..., 2, 1번 반복
- 원소교환은 상수 시간 작업
(n-1) + (n-2) + ... + 2 + 1 = O(n2 )
3. Insertion Sort (삽입정렬)
자료 배열의 모든 요소를 앞에서부터 차례대로 이미 정렬된 배열 부분과 비교하여, 자신의 위치를 찾아 삽입함으로써 정렬을 완성하는 알고리즘이다.
배열이 길어질수록 효율이 떨어지지만, 구현이 간단하다는 장점이 있다.
선택 정렬이나 거품 정렬과 같은 같은 O(n2) 알고리즘에 비교하여 빠르며, 안정 정렬이고 in-place 알고리즘이다.
버블, 셀렉션 정렬은 비교횟수가 동일하지만 삽입정렬은 비교대상이 점점 증가한다.
insertionSort(A[], n)
{
for i <- 2 to n
A[1...i]의 적당한 자리에 A[i]를 삽입한다;
}
수행시간
- for 루프는 n-1 번 반복
- 삽입은 최악의 경우 i-1번 비교
시간복잡도의 Worst case와 Average case 모두 O(n2) 이다.
W.C : 1 + 2 + ... + (n-2) + (n-1) -> 역순으로 정렬되어 있는 경우
A.C : 1/2(1 + 2 + ... + (n-2) + (n-1))
4. Merge Sort (합병정렬, 병합정렬)
합병 정렬은 다음과 같이 작동한다.
- 리스트의 길이가 0 또는 1이면 이미 정렬된 것으로 본다. 그렇지 않은 경우에는
- 정렬되지 않은 리스트를 절반으로 잘라 비슷한 크기의 두 부분 리스트로 나눈다.
- 각 부분 리스트를 재귀적으로 합병 정렬을 이용해 정렬한다.
- 두 부분 리스트를 다시 하나의 정렬된 리스트로 합병한다.
mergeSort(A[], p, r)
{
if (p < r) then {
q <- (p+r)/2; //p,r의 중간 지점 계산
mergeSort(A, p, q); //전반부 계산
mergeSort(A, q+1, r); //후반부 계산
merge(A, p, q, r) // 병합
}
}
merge(A[], p, q, r)
{
정렬되어 있는 두 배열 A[p...q]와 A[q+1...r]을 합하여
정렬된 하나의 배열 A[p...r]을 만든다
}
시간복잡도
T(n) = 2 * T(n/2) + cn
T(1) = 1
O(nlogn)
5. Quick Sort
다른 원소와의 비교만으로 정렬을 수행하는 비교 정렬의 종류.
퀵 정렬은 분할 해결 전략을 통해 리스트를 정렬한다.
- 리스트 가운데서 하나의 원소를 고른다. 이렇게 고른 원소를 피벗이라고 한다.
- 피벗 앞에는 피벗보다 값이 작은 모든 원소들이 오고, 피벗 뒤에는 피벗보다 값이 큰 모든 원소들이 오도록 피벗을 기준으로 리스트를 둘로 나눈다. 이렇게 리스트를 둘로 나누는 것을 분할이라고 한다. 분할을 마친 뒤에 피벗은 더 이상 움직이지 않는다.
- 분할된 두 개의 작은 리스트에 대해 재귀적으로 이 과정을 반복한다. 재귀는 리스트의 크기가 0이나 1이 될 때까지 반복된다.
재귀 호출이 한번 진행될 때마다 최소한 하나의 원소는 최종적으로 위치가 정해지므로, 이 알고리즘은 반드시 끝난다는 것을 보장할 수 있다.
quickSort(A[], p, r)
{
if (p < r) then {
q = partition(A, p, r) //분할
quickSort(A, p, q-1); //왼쪽 부분배열 정렬
quickSort(A, q+1, r); //오른쪽 부분배열 정렬
}
}
partition(A[], p, r)
{
배열 A[p....r]의 원소들을 A[r]을 기준으로 양쪽으로 재배치하고
A[r]이 자리한 위치를 return 한다.
}
6. Heap Sort
Heap : Complete binary tree로서 다음의 성질을 만족한다.
- 각 노드의 값은 자신의 childeren의 값보다 크지 않다.
Heapsort : 주어진 배열을 힙으로 만든 다음, 차례로 하나씩 힙에서 제거함으로써 정렬한다.
heapSort(A[], n)
{
buildHeap(A, n) //힙 만들기
for i <- n downto 2 {
A[1] <-> A[i]; //교환
heapify(A, 1, i-1);
}
}
최악의 경우애도 O(nlogn) 시간 소요.
Min Heap : complete binary tree & min tree
Max Heap : complete binary tree & max tree
Heap은 Array를 이용해서 표현할 수 있다. ( 완전 이진 트리이기 때문에)
배열 표현의 장점 : parent와 child의 관계가 일정하다.
'Algorithm' 카테고리의 다른 글
| STL이란 (0) | 2014.11.13 |
|---|---|
| round off, truncation error (0) | 2014.10.29 |
| B트리 (0) | 2014.10.17 |
| 디자인패턴 observer (2) | 2014.10.17 |
| quick sort (0) | 2014.10.17 |